Кодтау сөздігі әдісімен RDF әлсіз құрылымдалған деректерді Hadoop-MapReduce арқылы параллельді сығу және қалпына келтіру алгоритмі

Жұмыс түрі: Дипломдық жұмыс
Тегін: Антиплагиат
Көлемі: 38 бет
Таңдаулыға:
Кіріспе3
Негізгі бөлім6
1. Теориялық бөлімі6
1. 1 Әлсізқұрылымдалған деректер6
1. 2 Онтологиялар7
1. 3 RDF моделі10
1. 4 Hadoop-MapReduce технологиясы14
1. 5 Кодтау сөздігі17
2. Тәжірибелік бөлім20
2. 1 Онтология құру20
2. 2 RDF моделін құру22
2. 3 Hadoop орнату және баптау24
2. 4 Кодтау сөздігінің тізбектелген алгоритмін жасау29
2. 5 Кодтау сөздігі параллелді сығу алгоритмін жасау32
2. 6 Кодтау сөздігі параллелді қалпына келтіру алгоритмін жасау37
Қорытынды41
Қолданылған әдебиеттер тізімі42
А қосымшасы
Б қосымшасы
В қосымшасы
Г қосымшасы
КіріспеӨзектілігі
Қазіргі Web-тің күрделірек мәселелері туындады: Web-технологиялар әйгілілігі мен арзандығынан туындаған ақпараттық толу мөлшерінің өсуі және желідегі ақпараттың көрсетілімінің форматы бағдарламалық агенттерге ыңғайсыз болуы. Web-кеңістікте қажетті ақпаратты іздеу қиындай түсті. Сондықтан Internet кейінгі дамуын көптеген ғалымдар Семантикалық Web (Semantic Web) концепциясымен байланыстырады. Бұл концепция бойынша ақпарат көлемі ықшамдалуы тиіс, ал компьютерлер ақпараттарды «түсінуі қажет». Семантикалық Веб RDF ресурс сипаттау ортасы моделі көмегімен жасалған облыстардың кең диапазонында ақпараттарды сипаттайтын көптеген миллиардтаған пайымдауларға ие, бұл облыстар диапазоны медико-биологиялық ақпараттан мемлекеттік ақпаратқа дейін болады. Бірмәнділікті қамтамасыз ету үшін, URI ұғым идентификациясында жиі пайдаланылады. Терминдар URI ұзын тізбектерінен құралатындықтан, Semantic Web қосымшалардың көбісі, мысалы, RDF сақтау құралдары, кеңістікті сақтау және өнімділік арттыру үшін пайымдауларды компактілеу көрсетілімдерімен алмастырады. Деректердің осы үлкен көлемдерін ең жақсы өңдеу және жоғары өнімділік үшін RDF қосымшалар деректерді сығу тәсілдерін қолдануы қажет. Өкінішке орай, кіріс деректердің үлкен көлемдеріне байланысты сығу күрделі есеп болып отыр. Сондықтан MapReduce үлестірілген алгоритмдері RDF деректердің үлкен көлемдерін сығу және қайта қалпына келтіруде аса тиімді.
Жаңалығы
Семантикалық Web-та берілген деректер көбіне үлкен көлемде болады, ал үлкен көлемді деректер өңдеу көп уақыт шығынын келтіруі мүмкін. Сондықтан казіргі кезде дамып келе жатқан параллельді бағдарламалау, соның ішінде Hadoop-MapReduce технологиясын қолдану үлкен көлемді деректерді тиімді әрі жылдамырақ өңдеуге мүмкіндік береді. Соның ішінде жаңадан дамып келе жатқан Семантикалық Веб негізі болып табылатын RDF деректерді сығу және қайта қалпына келтірудің жаңа үлестірілген әдісі осы жұмыста жүзеге асырылды.
Тәжірибелік маңыздылығы
Бұл дипломдық жұмыс тәжірибелік маңыздылығы - бағдарламаланған әлсіз құрылымдалған деректерді семантикалық өңдеу мысалы, яғни деректердің RDF форматында берілген көлемін Hadoop-MapReduce технология көмегімен сығу және қайта қалпына келтірудің бағдарламалық реализациясы.
Қазіргі жағдайды бағалау
Интернет - қашан да қолданыста болған ақпараттық репозиторийлердің ең ірісі, әрі оның мазмұны әрдайым өсіп келеді және ол түрлі тілдерде, білімнің айтарлықтай барлық салаларында берілген. Бірақ ақырында осы бүкіл мазмұннан негізгі мағына табу қиындап барады. Іздеу жүйелері белгілі бір сөздерден тұратын ақпаратты табуға қабілетті, бірақ оның әрдайым қажетті ақпарат болуы екіталай. Әрқашан белгілі бір элемент қалдырылып кетеді. Іздеу мазмұнның семантикалық мағынасына немесе парақ туралы ақпаратқа емес, парақтардың мазмұнына негізделген. Семантикалық интернет құрылысымен бірден ол интернеттің бүкіл мазмұнын, ақпараттың әрбір элементінің сипаттамасын және осы элементтердің семантикалық мағынасының қамтамасыз етілуін белгілеуге мүмкіндік беретін болады. Осылайша іздеу жүйелері қазіргі жағдайымен салыстырғанда әлдеқайда тиімдірек болады, ал қолданушылар өздеріне қажетті ақпараттың нақ өзін табатын болады. Түрлі қызметтер көрсететін ұйымдар оларды ерекше мағынамен индекстеуге қабілетті. Ал қолданушылар интернет негізінде бағдарламалық құралдарды пайдалана отырып, осы қызметтерді жедел түрде табуға және оларды өз пайдасына немесе басқа қызметтермен сәйкестілікте қолдануға қабілетті болады.
Қазіргі кезде Веб-тің орнын Семантикалық Веб ығыстыра бастауда. Семантикалық Веб толық өз орнын алып, нық отыруы үшін, оның өнімділік мәселелерін шешу қажет. Сол мәселелердің бірі болып, Семантикалық Веб көп бөлігін құрайтын RDF деректер көлемінің тым үлкендігі, желі арқылы тасымалдау қиындығы, өңдеу жұмыстарының көп уақыт алуы. Нәтижесінде RDF қосымшалардың жұмыс өнімділігі төмендейді, мәселе шешімі ретінде Hadoop-MapReduce технологиясы көмегімен деректерді сығу және қайта қалпына келтірудің параллелді тиімді нұсқасы ұсынылып отыр.
Мақсаты
Семантикалық Веб негізі болып табылатын әлсізқұрылымдалған RDF деректерді Hadoop-MapReduce технологиясы көмегімен сығу және қалпына келтіруінің параллельді алгоритмінің бағдарламасын дайындау.
Есептері
1. Белгілі бір пәндік облыс таңдап, сол облысқа білім қорын жасау, дәлірек айтқанда, RDF моделінің синтаксисі пәндік облысын таңдау, білім қоры ретінде онтология құру.
2. Онтологияны RDF форматқа келтіру қажет. Арнайы бағдарламалық қамтамасында тексеру.
3. Кодтау сөздігінің сығу және қайта қалпына келтірудің тізбектелген нұсқадағы алгоритмін жүзеге асыру.
4. Кодтау сөздігі сығуының үлестірілген алгоритмін Hadoop-MapReduce технологиясы көмегімен Java тілінде жүзеге асыру.
5. Кодтау сөздігі қайта қалпына келтіру үлестірілген алгоритмін Hadoop-MapReduce технологиясы көмегімен Java тілінде жүзеге асыру.
Дипломдық зерттеу обьектісі
Семантикалық Веб негізі болып табылатын RDF әлсізқұрылымдалған деректерін өңдеу, дәлірек айтқанда сығу және қайта қалпына келтіру алгоритмдері.
Теориялық және методикалық негізі
Әлсізқұрылымдалған деректер семантикалық талдау кезінде RDF моделіне келтіріледі. Әдетте бір пәндік облысқа қатысты RDF деректер көлемі өте үлкен болады, ал деректерді өңдейтін қосымшалар деректер көлемін азайту үшін сығу әдістерін пайдалануы қажет болып отыр. Бұл дипломдық жұмыс негізі RDF деректерді Кодтау сөздігі әдісімен сығу және қайта қалпына келтіру алгоритмін Hadoop-MapReduce технологиясы көмегімен параллельді түріне келтіріп жүзеге асыру.
Дипломдық жұмыс жазылуының тәжірибелік базасы
Онтология Protеgе білім қорын құру ортасында жасалынды. RDF деректер Sesame RDF деректерді өңдеу және сақтау ортасында өңделді. Сығу және қалпына келтіру бағдарламасы Java тілінде Eclipse интеграцияланған әзірлеу ортасында Jena - арнайы RDF деректермен жұмыс істеуге арналған кітапханасы және Jena Elephas - Jena-ның Hadoop-қа арналған кітапханасын қолдану арқылы әзірленді. Үлестірілген параллелді есептеулер Hadoop MapReduce ортасында жалған үлестірілген тәртіпте жүзеге асырылды, яғни бағдарлама кластер үшін жазылып, бірақ бір машинада ғана орындалды.
Негізгі бөлім
1. Теориялық бөлімі
1. 1 Әлсізқұрылымдалған деректер
Әлсізқұрылымдалған деректер (жартылай құрылымдалған немесе нашар құрылымдалған деректер) - реляциялық деректер қорының моделіндегі кестелер мен қатынастардың қатаң құрылымына сәйкес келмейтін болса да, семантикалық элементтерді бөлетін және деректер тізімінде жолдар мен жазбалардың иерархиялық құрылымын қамтамасыз ететін тегтер мен басқа маркерлері бар, құрылымдалған деректер қалыбы. Сонымен, мұндай деректер түрін сызбасыз (schemaless), ал құрылымын - өзін-өзі сипаттайтын деп атауға болады.
World Wide Web-та берілген деректердің көп бөлігін әлсіз құрылымдалған, яғни қандай-да бір семантикалық құрылымы бар, бірақ деректер сызбасына ұқсайтын олардың құрылымдары туралы ақпарат олардың өзінде болуы мүмкін деректер түрінде қарастырған жөн.
Басқа да көзқарастар бойынша нақ деректер сызбасының маңызы әлсізқұрылымдалған деректердің дәстүрлі деректерден негізгі кілттік айырмашылығы болып табылады. Әлсізқұрылымдалған деректердің ерекшеліктерін сипаттайтын кілттік ережелерді атап өтуге болады:
- Деректердің тұрақты сызбасы болмайды;
- Деректер өзі мен олардың сызбасын арасында анық айырмашылығы жоқ;
- Қатал типизация жоқ;
- Деректер сызбасын өзгерту деректерге өзгертулер енгізу тәрізді қалыптасқан операция болады;
- Деректер көлемі олардың сызбасының күрделілігімен салыстырымды;
- Деректер сызбасы көрсетуші емес, сипаттаушы болып табылады, және де деректер өзінен алынуы мүмкін;
- Сұраныстарды құру үшін деректер сызбасын толық білу қажетті емес, деректер сызбасын толық ескермейтін сұраныстар да болу мүмкін.
Әлсізқұрылымдалған деректерде бір класқа жататын бүтіндіктерде түрлі атрибуттар болуы мүмкін. Атрибуттар тәртібі де маңызды емес.
Әлсізқұрылымдалған деректер зерттелуі керек маңызды объект болып табылады бірнеше себепке байланысты:
- Веб тәрізді деректер негіздеріне деректер қорына сияқты қатынау ыңғайлы, бірақ Веб-ті қандай-да бір анықталған деректер сызбасына келтіруге болмайды;
- Түрлі деректер қорлары арасында деректер алмасу үшін ең икемді фозматқа ие болғаны жөн;
- Құрылымдалған деректермен жұмыстың өзінде навигация мақсатымен оларды әлсізқұрылымдалған деректер түрінде көрсетілімі ыңғайлы.
Сонымен, әлсізқұрылымдалған деректер жиірек кездесетін болды, өйткені интернет дамуымен толықтексттік документтер және деректер қорлары үшін ақпараттық дәнекерлеуші сапасында қызмет ететін деректер форматы қажет. Әлсізқұрылымдалған деректерді объектіге-бағытталған деректер қорында жиі кездестіруге болады.
1. 2 Онтологиялар
Онтологиялар (гр. on (ontos) - болмыс) семантикалық желінің негізін құрайды және қандай да бір пәндік облыстың ұғымдары мен олардың арасындағы қатынастардың қандай да бір формалды тілдегі сипаттамасы болып табылады. Онтологиялар көбіне тезаурустар мен таксономияларға ұқсас болып келеді, бірақ шынымен олармен салыстырғанда кең болып табылады, өйткені сипатталатын деректердің құрылымын сипаттайтын қосымша құралдармен қамтамасыз етіледі. Онтологиялар өз мағынасында - ақпарат туралы ақпарат болғандықтан, олар метадеректер болып табылады.
Адамдар немесе бағдарламалық агенттер бірге қолдануында, пәндік облыстағы білімді жинақтау және қайта қолдану мүмкіндігі үшін, қатаң құрылымдалған деректермен ғана емес, онтологиялармен де жұмыс істейтін моделдер мен бағдарламалар жасау үшін, пәндік облыстағы білімді талдау үшін және т. б. мақсаттарда онтологиялар жасалынып және қолданыла алады.
Онтологиялардың көбісінің ортасында, әрқайсысында ағымдағы класпен салыстырғанда дәлірек ұғымдарды келтіретін ішкі кластары бар болуы мүмкін кластар болады. Онтологияның барлық кластары бір немесе бірнеше иерархия құрып пәндік облыс ұғымдарын сипаттайды. Кластарда ұғымдардың қасиеттерін және класс негізінде жататын ішкі құрылымын сипаттайтын атрибуттары болу мүмкін. Барлық ішкі кластар аталық кластар атрибуттарын мұрагерлікке алады. Кластың әр атрибутында атымен қатар, мән типі, рұқсат етілген мәндер және мәндер саны (қуаты) болады. Атрибут мән типі атрибуттың мәнінің қандай типтері болуы мүмкіндігін сипаттайды, мысалы, жол немесе бүтін сан. Атрибуттың тек белгілі бір кластарды немесе кластардың белгілі бір экземплярларын ғана қабылдайтын мән шектеулері де болады. Атрибут рұқсат етілген мәндері атрибутқа шектеулер қояды, бірақ тип шектерінде орындалады, мысалы, бүтін сандардың берілген диапазоны. Атрибут қуаты ол қанша мәнге ие бола алатындығын көрсетеді: тек бір мән - бірлік қуат немесе мәндердің кез келген саны - көптік қуат. Онтологияда класс экземплярлары болуы мүмкін, яғни барлық атрибуттарының мәндері орнатылған кластар болуы мүмкін.
Онтологиялар білім көрсетілімі, білім инженериясы, ақпараттық ресурстар семантикалық интеграциясы, ақпараттық іздеу және т. б. салаларда жеткілікті түрде кең таралды. «Жасанды интеллект» ғылымында онтология - бұл «пәндік облыс концептуализациясының спецификациясы», немесе қарапайымдатып айтқанда, терминдар арасында қатынастарды формалды беретін документ немесе файл. Бұл өзіндік тұрғыда пәндік облыстың ұғымдар сөздігі және осы ұғымдар мағыналарына қатысты анық айқындалған пікірлер жиыны болып табылады.
Көбіне онтология - кейбір анықталған түрдегі қатынастармен байланысқан ұғымдар иерархиясы түрінде көрсетіледі. Мұндай онтологиялар анықтамалары түрлі классификацияларда қолданылады. Дамыған онтологиялар логика тілінің құралдарымен қалыптастырылады және логикалық қорыту мүмкіншіліктеріне ие болады. Мысал түрінде «1. 1 - суретте» үйрету контексті атты кішігірім пәндік облыстың онтологиясының иерархиясын көруге болады.
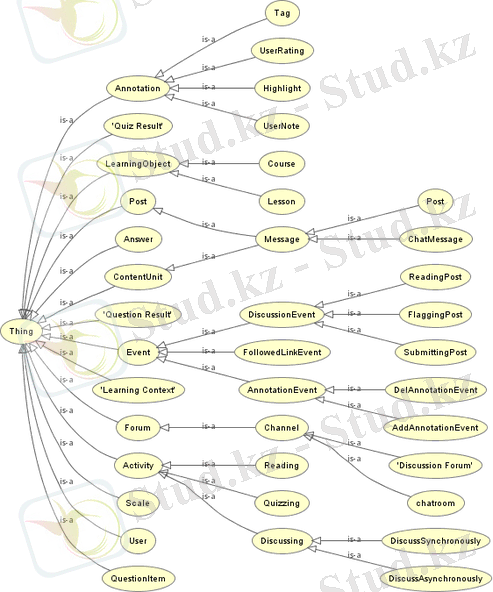
1. 1 - сурет. Үйрету контексті пәндік облысының онтологиясы
Ең қарапайым жағдайда онтологияларды Internet-те іздеу дәлдігін арттыру үшін қолдануға болады - іздеу жүйесі ізделінетін ұғым мәтіндерде жай кездескен емес, ал дәл мағынасында ескерілетін сайттарды ғана көрсетететін болады.
OWL веб-онтологиялар тілі - бұл веб-онтологияларды анықтайтын және көрсететін тіл. OWL формалды семантикасы онтология көмегімен логикалық салдарды қалай алуға болатынын сипаттайды, яғни онтологияда тікелей көрсетілмеген, бірақ оның семантикасынан шығатын факт алуды сипаттайды. Бұл салдар бір документке немесе OWL-дың белгілі бір механизмдерін қолдану арқылы комбинацияланатын бірнеше үлестірілген документтерге негізделіп алынуы мүмкін.
OWL веб-онтологиялар тілін W3C Web Ontology (WebOnt) жұмыстық тобы әзірлейді. OWL XML/Web стандарт болып табылады, бірақ одан айырмашылықтары бар.
Онтологиялардың XML схемаларынан ерекшелігі: бұл білім көрсетілімі, ал хабарламалар форматы емес. Веб-стандарттардың көбісі хабарламалар стандарттары және хаттамалар спецификацияларының комбинациясынан тұрады. Бұл форматтарға эксплуатациялық семантика берілген, мысалы: «СатыпАлуТапсырыс хабарламасын алғанда, теңге Мөлшерін СатыпАлушыЕсепшотынан СатушыЕсепшотына жіберу және Тауарды босату керек. » Бірақ спецификация берілген транзакция контекстінен тыс операцияларды қолдамайды. Мысалы, ереже бойынша, Тауар аты Шардоне болғандықтан, ол сонымен қатар ақ вино болатынын қорытындылай алатын механизм жоқ.
OWL онтологияларының артықшылықтарының бірі олар туралы пайымдай алатын құралдар қолжетімділігі болып табылады. Құралдар берілген пәндік облыстың өзіне тән емес жалпы қолдауды қамтамасыз етеді. Айқын және жұмыс істеуге қабілетті пайымдау жүйесін құру - қарапайым іс емес. Онтология құру қолжетімділігі жоғарылау.
OWL негізіндегі Web онтологиялық тілінің компоненттері.
OWL негізгі компоненттері кластарды, қасиеттерді және жеке элементтерді қамтиды.
Кластар
Кластар - бұл OWL онтологиясының негізгі блоктары. Класс - бұл домендегі концепция. Әдетте, кластар таксономиялық иерархияны құрады (яғни класс асты - класс үсті жүйесі) .
Кластар owl: Class элементі арқылы анықталады. OWL тілінде алдын-ала анықталған екі класс бар: owl:Thing және owl:Nothing. Бұлардың біріншісі әлдеқайда ортақ болып табылып, бәрін қамтиды, екіншісі - бос класс. Қолданушымен анықталатын кез-келген класс owl:Thing класының класс асты және owl:Nothing класының класс үсті болып табылады. Банк ісі саласындағы кластардың мысалдары Шот (Account) немесе Клиент (Customer) кластарын қамтуы мүмкін.
OWL класының мысалы:
<owl:Class rdf:ID="SavingsAccount">
<rdfs:subclassOf rdf:resource="#Account"/>
</owl:Class>
Мысалдағы код SavingAccount элементі Account класының класс асты болып табылатын класс екенін көрсетеді.
OWL кластарды сипаттаудың негізгі алты тәсілін қолдайды. Ең қарапайымы - бұл атауы (named) бар класс. Басқа тұрпаттары - бұл қиылыстар (intersection), бірлестіктер (union), шектеуліктер (restrictions) кластары және аударымдар (enumerated) кластары. Мысалда осы сыныптарды сипаттау тәсілдерінің екеуі берілген: SavingAccount шектеуліктер класын Account деп аталатын кластың класс асты ретінде анықтайды. W3C OWL кластарының қасиеттерінің толық пакетіне сілтемені Ресурстар бөлігінен табуға болады.
Қасиеттер
Қасиеттер екі негізгі санатқа бөлінеді:
- объекттік қасиеттер (Object properties), бұлар жеке элементтерді өзара байланыстырады;
- деректер типтік қасиеттер (Datatype properties), бұлар жеке элементтерді бүтін сандар, құбылмалы үтірі бар сандар және жолдар тәрізді деректер типтерінің мағыналарымен байланыстырады.
OWL деректердің типтерін анықтау үшін XML жүйесін қолданады. Қасиеттер доменді және сонымен байланысты кейбір саланы қамтуы мүмкін. Кез-келген қасиет келесі санаттардың біріне кіреді:
- функционалдық: кез-келген объект үшін қасиет тек бір мағына ғана қабылдауы мүмкін (мысалы, адамның жасы, бойы және салмағы) ;
- кері-атқарымдық: түрлі екі жеке элемент бірдей мағынаға ие бола алмайды. Мысалы, кез-келген адамның банк шотының бірегей нөмірі болады немесе SSN (social security number) ;
- симметриялық: егер қасиет А элементін В элементімен байланыстырса, онда бұдан оның солайша В элементін де А элементімен байланыстыратыны туралы қорытынды жасауға болады. Симметриялық қасиеттердің мысалдары «ағасы (әпкесі) болып табылады» немесе «сондай сияқты» деген тәрізді мағыналарды қамтиды;
- транзитивтік: егер қасиет А элементін В элементімен байланыстырса, ал В элементі С элементімен байланыстырса, онда ол А элементін С элементімен де солайша байланыстырады деп болжауға болады. Мысалы, егер А В-дан жоғары болса, ал В С-дан жоғары болса, онда А С-дан жоғары.
Кластар мен қасиеттерге түрлі шектеулер қойылуы мүмкін. Мысалы, көпшілік қуаттылығының шектеулері класс немесе жеке элемент қатыса алатын байланыстар санын көрсетуі мүмкін.
1. 3 RDF моделі
Семантикалық Web технологияларына келесілер кіреді:
- аттардың жаһандық тәсімі (URI) ;
- деректер сипаттамасының стандарттық синтаксисі (RDF) ;
- деректердің қасиеттерін сипаттаудың стандарттық тәсілдері (RDF схемасы) ;
- деректердің объектілерінің арасындағы байланысты сипаттаудың стандарттық тәсілдері (Web онтологиялық тілінің көмегімен анықталатын онтология (Web Ontology Language) ) .
RDF - желіде ақпарат көрсетіліміне арналған платформа, децентрленген әлемдегі білім көрсетілімінің тәсілі, Семантикалық Веб негізгі технологиясы. RDF - бұл қатаң мағынада XML-формат емес, қарапайым метадерек емес.
RDF моделі 90-шы жылдар соңында пайда болды, ал 2001 жылы Scientific American журналында семантикалық тор кезеңі келгенін жариялаған (Semantic Web) Тим Бернерс Лидің әйгілі мақаласы [3] жарық көрді. Сол шақтан бастап желіде семантикалық өңдеумен байланысты барлық нәрсеге, соның ішінде RDF-ке де қызығушылық дереу артты, ал 2004 жылы RDF W3C комитетінің стандарты түрінде қабылданды. Стандарт бойынша семантикалық Веб ұғымдар стегінде RDF орнын 1. 2 - суретте көруге болады.
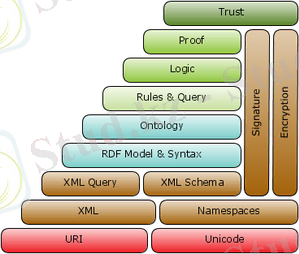
1. 2 - сурет. Семантикалық Веб ұғымдар стегі
RDF [32] негізі - бұл субьекттан обьектқа бағытталған байланысты сипаттайтын деректердің субъект-предикат-объект (үштік, triples) пайымдаулары түріндегі көрсетілімі. 1. 3 - суретте үштік сызбасы бейнеленген.

1. 3 - сурет. RDF үштігі
RDF спецификациясында желілік ресурстар арасында қатынастар құру қағидаты үш компонент болуын қарастырады - объект, атрибут және мәні («бастауыш - баяндауыш - толықтауыш» классикалық сызбасының аналогы) . Берілген тізбектің (триплет) әр элементіне идентификатор (URI) беріледі, оның көмегімен түйіндердің біреуіне сілтеу арқылы автоматты түрде тізбекті толығымен қайта қалыптастыруға болады. RDF тілінің триплеттерінен өзара байланысқан желі қалыптаса алады. RDF ақпаратты документте кодтау үшін URI-идентификаторлар қолданатындықтан, бұл әр ұғым Желіде табуға болатын бір анықтамаға бекітілуін қамтамасыз етеді.
RDF негізгі құрылыс блогы - «объект - атрибут - мәні» үштігі көбіне A(O, V) түрінде жазылады, мұндағы О - объект, А - V мәнді атрибут. RDF объекттер мен мәндер орындарын ауыстыруға рұқсат береді.
Бастапқыдан RDF-та объекттер, ұғымдар, қасиеттер және қатынастар сәлтемелері үшін XML тілінің синтаксисі және URI-идентификаторлар қолданылады. Бірақ RDF-сипаттамалардың басқа түрлері де бар, мысалы, үштіктер тізбегі түрінде:
hasName
("http://dwl. visti. net", "Dmitry Lande")
authorOf
("http://dwl. visti. net/", "ISBN5845907640")
hasPrice
("ISBN5845907640", "$8") .
Сонымен қатар, RDF үштік түріндегі кез келген RDF пікір объект немесе мән болуына рұқсат береді, яғни берілген объектте белгілі бір тип бар екендігін нұсқауға мүмкіндік береді, мысалы, "ISBN5845907640" - бұл rdf:type book, RDF сызбасында book анықтамасына сілтеу арқылы:
<rdf:Description about="www. book. net/ISBN5845907640">
<rdf:type rdf:resource="http://description. org/schema/#book">
</rdf:Description>
RDF үштігің құрамының үш компоненті:
- субъект: RDF URI сілтемесі немесе бос түйін болады;
- предикат: RDF URI сілтеме болады;
- объект: RDF URI сілтеме, литерал немесе бос түйін болады.
Субъекттер, объекттер және предикаттар идентификациясы үшін URL ұғымының жалпылануы болып табылатын Uniform Resource Identifier (URI) идентификаторы қолданылады. Мысалы:
субъект/объект:
http://localhost/publications/articles/Journal1/1940/Article1.
Предикат:
<http://purl. org/dc/elements/1. 1/title>.
RDF граф - RDF триплеттер жиыны.
RDF - бұл кез келген білімді кішкентай бөліктерге бөлетін әмбебап әдіс. Ол семантикаға, яғни сол бөліктер мағынасына қатысты белгілі бір ережелерді тағайындайды. Идеяның негізі - кез келген фактты бір қарапайым әдіспен сипаттауға болады, әрі бұл компьютерлік бағдарламалар өңдей алатындай құрылымдалған түрде жүзеге асырылады.
«1. 4 - суретінде» түйіндері субъект/объекттер болатын, байланыс доғалары предикаттар болатын, ал оларды анықтау үшін URI идентификаторы қолданылған RDF графының мысалы көрсетілген.
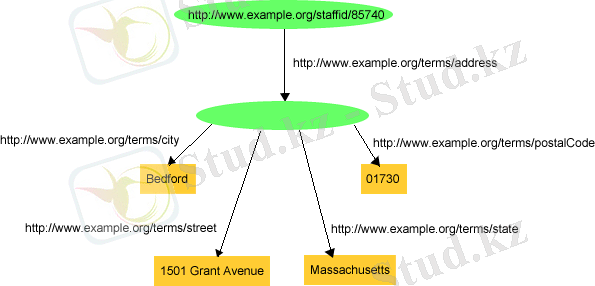
Сіз бұл жұмысты біздің қосымшамыз арқылы толығымен тегін көре аласыз.
- Іс жүргізу
- Автоматтандыру, Техника
- Алғашқы әскери дайындық
- Астрономия
- Ауыл шаруашылығы
- Банк ісі
- Бизнесті бағалау
- Биология
- Бухгалтерлік іс
- Валеология
- Ветеринария
- География
- Геология, Геофизика, Геодезия
- Дін
- Ет, сүт, шарап өнімдері
- Жалпы тарих
- Жер кадастрі, Жылжымайтын мүлік
- Журналистика
- Информатика
- Кеден ісі
- Маркетинг
- Математика, Геометрия
- Медицина
- Мемлекеттік басқару
- Менеджмент
- Мұнай, Газ
- Мұрағат ісі
- Мәдениеттану
- ОБЖ (Основы безопасности жизнедеятельности)
- Педагогика
- Полиграфия
- Психология
- Салық
- Саясаттану
- Сақтандыру
- Сертификаттау, стандарттау
- Социология, Демография
- Спорт
- Статистика
- Тілтану, Филология
- Тарихи тұлғалар
- Тау-кен ісі
- Транспорт
- Туризм
- Физика
- Философия
- Халықаралық қатынастар
- Химия
- Экология, Қоршаған ортаны қорғау
- Экономика
- Экономикалық география
- Электротехника
- Қазақстан тарихы
- Қаржы
- Құрылыс
- Құқық, Криминалистика
- Әдебиет
- Өнер, музыка
- Өнеркәсіп, Өндіріс
Қазақ тілінде жазылған рефераттар, курстық жұмыстар, дипломдық жұмыстар бойынша біздің қор #1 болып табылады.

Ақпарат
Қосымша
Email: info@stud.kz