Hadoop-та MapReduce арқылы гиперспектральды бейнелерді ISODATA алгоритмімен кластерлеуді жүзеге асыру

Қазіргі таңда дешифлеудің және объектің танылуын, жерде болатын құбылыстардың танылуның сенімділігін арттыру үшін көп мөлшерде жерді қашықтан зодтау әдісі қолданылады. Гиперспектральды бейнелерді өңдеу бағытының дамуын маңызды болуы себебі гиперспектральды бейнелерді өңдеу әдістері әліде кең түрде құрылмағандығы.
Гиперспектральді деректермен жұмыс істеу кезінде тек мықты есептеуіш машиналар ғана емес сонымен тағы бағдарламалық жабдықтауда қажет. Олар оз кезегінде спектральді рұқсат етілімдегі және үлкен кеңістіктегі бейнелердің жаңа дәуірімен жұмыс жасауға мүмкіндік береді. Кластерлеудің стандартты алгоритмдері әдеттегідей аз мөлшердегі каналдар санын өндеуде ғана тиімді болады.
ISODATA кластерлік алгоритмі қашықтан зондталған деректерді зерттеу облсында жалпы әдіс ретінде карастырылады. Бұл бейненің алдыңғы үлгісін құрғанға өте тиімде алгоритм болып табылады. Кластерлеудің бұндай әдістері қазіргі таңда персональді компьютерлерде құрылып жүзеге асырылады. Осыған қарамастан, қашықтан зондтау технологиясының дамуымен, кеңістік рұқсат етілімдері де тез өсіп келеді, және деректердің өлшемдеріде үлкейе түсуде. Үлкен көлемдегі бейнелерді персональді компьютерде кластерлеу аппараттық шектеулерден және бағдарламалық ресурстардың себебінен едәуір көп уақыт алады.
Hadoop - бұл үлкен көлемдегі деректерді өңдейтін үлестірмелі қолданбалылырды құруға және жіберуге арналған ашық нәтежилік коды бар қаңқа. Hadoop бейнелерді өңдеуге жақсы технология болып келеді, сондықтан біз оны қашықтан зондталған деректерді өңдеу үшін қолданамыз.
Жұмыстың мақсаты: Гиперспектральді бейнелерді өңдеу үшін ISODATA кластерлік алгоритмін Hadoop платформасында жүзеге асыру.
Қадамдар:
- ISODATA кластерлік алгоритмін зерттеу.
- Hadoop платформасын және оның HDFS файлдық жүйесін зерттеу.
- Hadoop платформасын орнату және оның функционалдылығын тестілеп көру.
- Hadoop платформасында ISODATA алгоритмін жүзеге асыру.
- Тәжербелік зерттеулер жасау және алынған нәтежиелерге қорытынды жасау.
Практикалық мағанасы: MapReduce парадигмасын қолдану бейнені өңдеу кезіндегі алгоритмның уақытын айтарлықтай қысқартты. Біздің тәжірбелерімізде есептеулер үлсетірмелі есептеулерге арналған Hadoop платформасында, MapReduce парадигмасын қолданып есептелінді. Hadoop платформасын қолдану бізге есептің есеплеуінің маштабын өзгертуге мүмкіндік берді, бірнеше есептеуіш түйндерде есептелуін қамтамасыз етті.
Жасалған тәжірбелерден үлестірмелі есептеулер есептеу жылдамдығын, түйндер санын көбейту арқылы сызықты түрде жылдамдатуға қол жеткізуге болады. Тағыда жасалған тәжірбелерден жай компьютерлерді қолданып, Hadoop платформасында үлкен көлемді деректерді өңдеуге тиімді екенін көреміз.
1 ЖЕРДІ ҚАШЫҚТАН ЗОНДТАУ ЖӘНЕ ГИПЕРСПЕКТРАЛЬДІ БЕЙНЕЛЕРДІ ӨҢДЕУ АЛГОРИТМДЕРІ 1. 1 Жерді қашықтықтан зондтауСоңғы он жылдықтарда жер беті жақта орналасқан объектiлердi дистанциялық зерттеуде үлкен табысқа ие болғанның бiрi тар спектрлiк ауқымдарды үлкен санды түрде ЖАЗ мәлiметтер алуға рұқсат беретiн көрсеткiштерiнiң жасауы болып табылады. Мәлiметтерлерiн гиперспектральды талдау туралы ақпаратты алшақ зерттелетiн объект толығырақ алуға рұқсат бередi. Гиперспектральды сурет қазiргi уақытта зерделеу үшiн және жердің бет жағынындағы объектiлерді картирлеу үшін белсене пайдаланылады. Мысалы: iздестiру үшiн және (органикалық заттың ылғалдық, ұстауы, тұздалу), туған жерлерiнiң картаға түсiруi, шөптесiндiк жамылқтың күйiн анықтау және тағы басқалар. Гиперспектральды мәлiметтермен жұмыс кезінде қуатты компьютерлер ғана емес, жаңа суреттердiң жаңа спектрлiк рұқсат та қажеттi жұмыс iстеуге рұқсат берген бағдарламалық қамтамасыз ету. ENVI программалық кешені гиперспектральді бейнелердiң және мультиспектрлiк талдауда лидер болғанын бүкiл әлемде мойындады [1-2] .
Әдетте арналарды түсті синтез жасағанда үш спектрлiк аймақ ғана пайдаланылады. Спектрлiк арналардың көптiк тiркесiмдері объектiлердің әр түрлi түрлерiнің шифрын анықтауға және оларды үлкейтуге көмектеседi, дегенмен гиперспектральді суреттiң жүздiк спектрлiк аймақтарын көзге елестету өте қиын, сондықтан мұндай мәлiметтерлердi көрсету үшiн «гиперспектральді текше» пайдаланылады 1. 1 суретте көрсетілген.
Қазiргi уақытта ЖАЗ суреттердi өңдеу және талдау үшiн игерiлген арнаулы программалық кешендер бар. Мысалдардың бiрi ENVI программалық кешендi болып табылады.

1. 1-Сурет. Гиперспектральді кубтың үлгісі
Бұл алгоритмдердің көпшiлiгін мультиспектрлiк суреттермен жұмыс үшiн пайдалануға болады, кейбір шектелген түрде болсада.
1. 2 ISODATA кластерлеудiң алгоритмі туралыISODATA алгоритімда негiзгi рәсiм орталықтарды теруден туған ең төменгi дистанциялық бөлiктеу болып табылады. Кластар саны алдын ала белгiлі емес, жiктеу барысында анықталады. Ол үшiн параметрлерiмен сипаттама класаралық реттелетiн қосалқы эвристикалық процедурлер қатарды және жiктеу iрiктеменiң тап iшiнде құрылымы кезеңде пайдаланады. [1] .
Кластерлер санының өзгерiсiнiң негiзгi рәсiмдерiн қарап шығамыз.
1. Кластерлердi жою. Егер кластер (ISODATA алгоритмның - параметрi) элементтерiнде i c -ден аз болса болса, ал кластерлердiң орталарының тiзiмiнен кластер центірі өшіріледі, яғни оның элементтерi басқа кластерлер бойымен үлестiредi.
2. Кластерлердi бөлу. Егер i дисперсия - болса -лер болса, егер элементтердiң кластердiң ортасынан шашылу әжептәуiр үлкен болса, онда i -шi кластер екi кластерде бөлiнедi:
Ары қарай l -ші құрауыш алынып, осыған қарай кезіндегі, барлық s ≠ l , болғанда i -ші кластер l құрауышы бойынша бөлінеді. Осымен бірге кластердің центрлері қайта саналады c′ және c′′ .
3. Кластерлердiң араласып кетуі. Егер екi кластерлердiң орталарының арасындағы қашықтық әжептәуiр аз болса, онда бұл кластерлер бiр кластерге топтастыру керек. Бұл рәсiмдi өткiзу үшiн екi кластерлердiң орталарының арасындағы қашықтықты есептейдi:
Егер көрсетсе, онда кластер және топтастыру керек. Жаңа кластердiң ортасы формула бойымен есептейдi
.
ISODATA алгоритмінде кластерлердiң санын реттейтiн тағыда басқа рәсiмдер болады. { x 1 , x 2 , . . . , x N }, терумен жұмыстың жасағанда, ISODATA N элемент жасалынған алгоритм x_N келесi негiзгi қадамдарды орындайды.
1-қадам . Кластерлеудiң процессін анықтайтын параметрлері беріледі:
К - кластердің керек саны;
Q N - кластер iшiне кiретiн бейнелердi санмен теңестіретін параметр;
Q s - орташа квадраттық ауытқуды сипаттайтын параметр;
Q c - ықшамдылықты сипаттайтын параметр;
L - топтастыруға болатын кластерлердiң орталарының ең жоғары саны;
I - итерация ықтимал циклдер саны.
2-қадам. Берiлген N бейнелер кластерлер бойынша жiктеледi
𝑥∈𝑆𝑗, егер х- zj <х- zi, i=1, 2, . . . , Nc; 𝑖≠𝑗
3-қадам. Құрамына Q N өйткенi элементтер кем кiрген бейнелердi көп астында жоғалтылады. егер j үшiн кейбiр N j < Q N шартты орындаса, онда S j iшкi жиын қарастырудан шығарады және N c мағынаны 1-ге азаяды.
4-қадам. z j , j=1, 2, . . . , N c әр кластердiң ортасы, оны теңестiру арқылы таратпайды және S j көп астында бойымен тиiстi табылған iшiнара орташа түзетiледi. N j - S j көп кiретiн объектiлердi санына кіреді.
5-қадам . S j көп кiрушi объектiлердiң арасындағы орта қашықтықты есептейдi, және формула бойымен тиiстi кластердiң ортасымен есептейді
.
6-қадам. Объектiлердiң арасындағы жеке кластерлерде орналасқан, және тиiстi кластерлердiң орталарының формула бойымен қорытылған орта қашықтықты есептейдi
7-қадам. (а) Егер итерацияның ағымдағы айналымы - соңғы болса, онда Q c =0 қояды ; 11-ші қадамға өтеді. (б) Егер N c <=К/2 -шi шартты орындаса, онда 8-шi қадамға өтеді. (в) Егер итерацияның ағымдағы айналымы жұп реттiк нөмiрге ие болса немесе N c >=2 K шартты орындаса, онда 11-ші қадамға өтеді; итерацияның процесi басқа жағдайда жалғасады.
8-қадам. Ара қатынастың көмегiмен әр iшiнара бейнелердi iшкi жиын үшiн
орташа квадраттық ауытқудың векторын есептейдi п бұл бейненiң өлшемдiгi
x ik , , k объектiнiң S j iшкi жиында i -шi құрауышы, z ij бұл i -шi z j кластердiң орта таныстыратын вектор құраушы, және S j iшкi жиын қосылған iшiнара бейнелердi N j - сан орташа квадраттық ауытқу әр вектор құраушы басты координаталар осьтардың бiрi бойымен S j iшкi жиын кiресiн бейне орташа квадраттық ауытқуды мiнездейдi.
9-қадам. J=1 орташа квадраттық ауытқу әр векторда, , j=1, 2, . . . , N c , ең жоғары құрамдас бөлiк iзделеді .
10-қадам. Егеркез-келген , j =1, 2, . . . , N c , шарты орындалады , және
а +1)
немесе
б) ,
болса онда кластер z j центрімен сәйкесінше және жаңа екі кластерге бөлінеді, кластер z j центрімен жойылады, ал N c мәні бірге көбейеді. z j , тиiстi ең жоғары вектор құраушыны кластердiң орта вектор құраушыға анықтамасы үшiн, берiлген шаманы ұзартылады ; кластердiң ортасы - бұл шаманы шегерумен анықталады z j вектор құраушы соның өзiненiң. қойсын . Негiзгi сол таңдауда негiзге алу керек, үшiн кластерлеу жалпы құрылымды айтарлықтай өзгертпедi, бiрақ әжептәуiр аз, үшiн шама оны жаңа екi кластерлердiң орталарына кез келген бейнеден дейiн қашықтықтарындағын айырмашылықтың ажыратуы үшiн әжептәуiр үлкен болды.
Егер ыдырау бұл қадамда болса, керек қадамға 2 өтсiн, басқа жағдайда алгоритмның орындауын жалғастыру.
11-қадам. Кластерлердiң орталары арасындағы Dij қашықтығы барлық жұпты есептейдi:
Dij = zi - zj , i =1, 2, . . . , Nc-1; j = i +1, 2, . . . , Nc.
12-қадам. D ij қашықтық параметрiмен теңеседi. Сол L кем көрсететiн қашықтықтар, өсудiң ретi бойынша тұрғызады және
D i1j1 < D i2j2 < . . . < D iLjL,
Келесi адым кластерлердi араласып кетудiң процесiн жүзеге асырады.
[ D i1j1 , D i2j2 , . . . , D iLjL , ]
13-қадам. Әр анықталған центірлері z il және z jl болатын кластер жұбы үшін D iljl қашықтығы есептелінеді. Тiзбекте бұл жұптарға, центрлердiң арақашықтықтың тиiстi көбеюiне, келесi ереженi негiзі iске асатыны араласып кету iс ретiн қолданылылады.
Кластерлер z il орталарымен және z jl , i = 1, 2, . . . , L , (араласып кетудiң итерация iс ретi ағымдағы циклiнде не шарт кезiнде қолданылылмады не бұданға, не басқа кластерге) бiрiгедi
z il және z jl кластер центрлері жойылады, және N c мәні бірге кемиді.
Белгiлеймiз, кластерлерiн ғана жұп бойынша араласып кетуi рұқсат берген және кластердiң алынған нәтижесiнiң ортасы, бiрлестiрiлетiн кластерлерiнiң орта алынатын позициялардан сүйене және алынған iшiнара бейнелердi тиiстi кластерде сан анықталатын таразымен есеп айырысады.
Тәжiрибе кластерлердi бiрiктiру пайдалану күрделi процедурден астам қанағаттанарлықсыз нәтижелердi алуға мүмкiн әкелетiнiн туралы куәландырады. Суреттеп айтылған iс ретi бейнелердiң шынайы орташа қотарылатын iшкi жиын таныстыратын нүкте бiрiккен кластерiн ортаның сапасында таңдауды қамтамасыз етедi. Маңызды да көздегенi болу, себебi араласып кетудiң iс ретiн әр кластердiң ортасына осы қадамның бiр ғана, өткiзуi қолдануға болады не жағдайлар какихтың жанында L бiрiккен кластерлерiн алуға мүмкiн әкелу.
14-қадам. Егер итерацияның ағымдағы айналымы - соңғы болса, онда алгоритм орындауын тоқтатады. Егер қолданушының ұйғарымы бойымен кластерлеудiң процесс анықтайтын параметрлердiң қайсы бiр айырбастаса, басқа жағдайда кайту керек немесе 1-қадамға өтеді, немесе 2-ші қадамға, егер процестiң параметрлер итерацияның кезектi айналымында өзгерiссiз қалуы керек болса. Итерацияның циклын аяқтау 1-шi немесе 2-ші қадамға өткенде есептейдi.
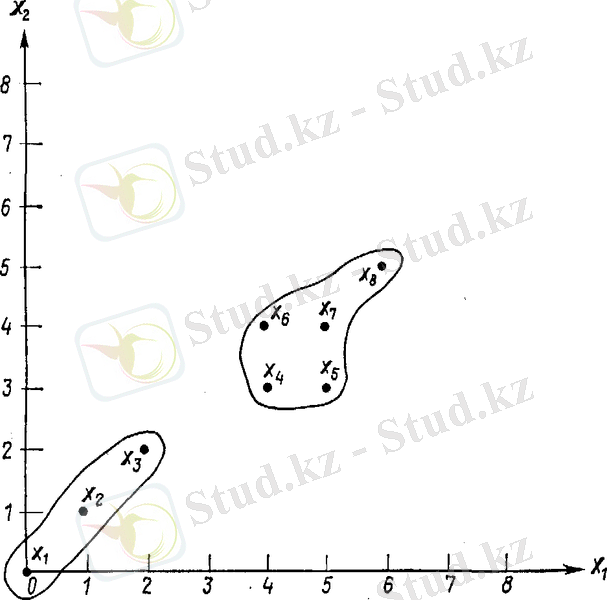
1. 2-Сурет. ISODATA алгоритмінің жұмыс істеу үлгісі
2 ЖЕРДІ ҚАШЫҚТАН ЗОНДТАУ ҮШІН MAPREDUCE ПАРАДИГМАСЫ 2. 1 Жердiң дистанциялық қашықтығын барлап байқауы үшiн MapReduce мүмкiндiгiн қолдануҒылыми зерттеулердi жүргiзудiң нәтижесiнде қазiргi дәрiгерлiк сканирлейтiн жабдықпен, физикалық эксперименттермен астрономиялық бақылаулар, жұмыс кескiндi жиi жасаған мұндай сияқты. Бұл кескiндер одан әрi түсiндiру үшiн компьютер өңдеуiне содан соң ұшырайды және ғылыми нәтижелердi алу. Қазiргi әлемдiк деңгейде зерттеулердi жүргiзуде мүмкiн жүз-жүздеп өлшенген кескiндердi үлкен көлем қалыптасады, және гигабайттың мыңдарымен. Мұндай көлемдердi тиiмдi өңдеу ғана қатарлас есептеуiш жүйелерге мүмкiн.
Қазіргі таңда әйгілі параллелді архитектуралар үлкен көлемді декектерді және бейнені өңдеуге жақсы келмейді. MPI пайдаланумен хабар берудiң негiзiнде қатарлас програмдарды әзiрлеуге тәсiл қолданылатын iс жүзiнде барлық жерде биiк күрделiлiкке ие болады және артық көбiнесе болып көрiнедi, өйткенi әдеттегiдей кескiн, бiр-бiрiнен тәуелсiз жұмыстана алады. Қатарлас есептеуiш жүйе қолданылатын сақтау жүйе биiк құндар ерекшеленедi, бiрақ бұл ретте жеткiлiктi өнiмдiлiктерге жиi ие болмайды.
Архитектураның әзiрлеуi және аталған кемшiлiктердi жоюдың есептеуiмен үлкен масштабпен қатарлас есептеуiш жүйелерге кескiндердiң үлкен көлемдерiн өңдеу үшiн программалық құралдар өзектi мiндеттi болып көрiнедi. Бiртiндеп программаны автоматты параллельдеудiң мүмкiндiгi бұл мұндай архитектурасына негiзгi талаптар - және серверлердiң iшкi дисктерiне деректерлердi сақтау үшiн таралған файл жүйесi.
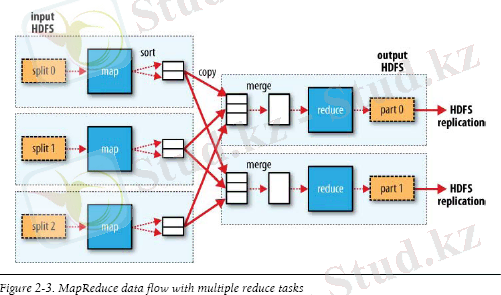
2. 1-Сурет. MapReduce парадигмасының екі қадамнан тұратындығы көрсетілген.
Қатарлас программалаудың технологиясын таңдау. Қатарлас программалаудың технологиясын таңдауда келесi талаптарды ескеру керек:
• әр бейненi өңдеу немесе бейнелердi тобы бiр-бiрiнен тәуелсiз болуы керек;
• таралған файл жүйесiнiң қолдауы;
• бiртiндеп бағдарламаны автоматты қатарластыру;
• үйреншiктi архитектураның серверлерiнен кластерiндегi жұмысты қолдауы.
Талаптары есептеуiмен қатарлас программалауының әйгiлi технологияларын салыстыру аталған жоғары 1 кестеде келтірілген.
1-Кесте. MPI, OpenMP және MapReduce технологияларын салыстыру
Кесте талдаудың негiзiнде бейнелердi өңдеу үшiн MapReduce технологияны жақсы барлығы жақындағанын қорытынды шығаруға болады. MapReduce таралған файл жүйесiн қосады. Технологияның маңызды шектеуi алгоритм MapReduce тәуелсiз есептерді қатарлас орындау бағдарлалған қолдау дұрыс емес болып көрiнедi. Дегенмен бейне немесе бейнелердi тобын тәуелсiз өңдеуге болады, сондықтан MapReduce қолдану мүмкiндігін ақтай алады [3-4] .
ISODATA технология MapReduce негiзделген кластерлеуге алгоритмның қатарлас өткiзуiн негiзгi ой функция Map ең жақын кластерге дейiн әр пиксельдiң жiктеуiнде қосылады және функция Reduce жаңа кластер орталықтарын есептеу [5-6] .
Кiретiн мәлiметтерде кiлт пайдалы ақпаратты алып жүрмейдi, бiрақ кiретiн мәлiметтердi құрылымға, әр пиксельдiң мағынасына сәйкес оның керекті R, G, B мағынадан тұратын жолы болады. Map функция кластер орталықтарын мағыналары бар пиксель алдымен мағынаны теңестiредi, ал кластер орталығына қай пиксель жақынырақ барлығы орналастырған содан соң анықтайды.
Map function Input:
(global object, in_key, in_value), global object contains the initial clustering centers, in_key has no usefulness, in_value is a string like (pixel_id, R, G, B) . Output: (out_key, out_value), out_key is a string represents a clustering center, out_value is a same string as in_value.
1: construct initial clustering centers Array from global object;
2: labPixel = parseString ( in_value ) ;
3: minDistance = MAX_VALUE;
4: = -1;
5: for (j = 0; j< Array. length; ++j) {
6: dist = (labPixel, Array[j] ) ;
if (dist < minDistance) { minDistance = dist; = j; } }
7: out_key = Array[] ;
8: out_value = in_value;
9: writeToHDFS(out_key, out_value) ;
10: output(out_key, out_value) ;
11: End;
1-қадамнан 4-қадамға дейiн - бұл ауыспалы инициализация, 6-шы қадам бастапқы кластер орталықтарының пиксель кiру нүктесiнің бiрiне дейiн қашықтықты есептейдi. 7-шi қадам циклда аяқтаудан кейiн және 8-шi қадам пиксел нүктесi жатқан кластер орталығын анықтайды. 9-қадамда және 10- қадамда HDFS шығыс файл жүйесiне кілт/мән жұп бөлек жазады.
Reduce функциясы: Бұл функция Map функциясынан алынған барлық кілт/мән жұптарын құрайды. Бір және сол кілтке ие барлық кілт/мән жұптары итераторда сақталады. Reduce функциясы сол кілттің орташа мәнін есептейді, бірақ барлық ортақ әдіске ие болатын мәнді қосады, жаппай есептеу шартында толуға әкеп соғады. Сондықтан формула бойынша жаңа орташа мәнді есептейтін стратегия қолданылады:
= + [ Pi - ] / ( + 1) (1)
мәні ағымдағы кілт/мән жұбын білдіреді. P i пиксельді нүктенің келесі мәнін білдіреді. [ P i - ] P i арасындағы айырмашылықты білдіреді және . жаңа орташа мәнді білдіреді.
Reduce функциясының псевдо-коды төменде көрсетілген:
... жалғасыСіз бұл жұмысты біздің қосымшамыз арқылы толығымен тегін көре аласыз.
- Іс жүргізу
- Автоматтандыру, Техника
- Алғашқы әскери дайындық
- Астрономия
- Ауыл шаруашылығы
- Банк ісі
- Бизнесті бағалау
- Биология
- Бухгалтерлік іс
- Валеология
- Ветеринария
- География
- Геология, Геофизика, Геодезия
- Дін
- Ет, сүт, шарап өнімдері
- Жалпы тарих
- Жер кадастрі, Жылжымайтын мүлік
- Журналистика
- Информатика
- Кеден ісі
- Маркетинг
- Математика, Геометрия
- Медицина
- Мемлекеттік басқару
- Менеджмент
- Мұнай, Газ
- Мұрағат ісі
- Мәдениеттану
- ОБЖ (Основы безопасности жизнедеятельности)
- Педагогика
- Полиграфия
- Психология
- Салық
- Саясаттану
- Сақтандыру
- Сертификаттау, стандарттау
- Социология, Демография
- Спорт
- Статистика
- Тілтану, Филология
- Тарихи тұлғалар
- Тау-кен ісі
- Транспорт
- Туризм
- Физика
- Философия
- Халықаралық қатынастар
- Химия
- Экология, Қоршаған ортаны қорғау
- Экономика
- Экономикалық география
- Электротехника
- Қазақстан тарихы
- Қаржы
- Құрылыс
- Құқық, Криминалистика
- Әдебиет
- Өнер, музыка
- Өнеркәсіп, Өндіріс
Қазақ тілінде жазылған рефераттар, курстық жұмыстар, дипломдық жұмыстар бойынша біздің қор #1 болып табылады.

Ақпарат
Қосымша
Email: info@stud.kz