Қолданбалы есептерге параллельді алгоритмдерді қолдану: сұрыптау алгоритмдерін MPI арқылы іске асыру және талдау

Жұмыс түрі: Курстық жұмыс
Тегін: Антиплагиат
Көлемі: 30 бет
Таңдаулыға:
ҚАЗАҚСТАН РЕСПУБЛИКАСЫНЫҢ БІЛІМ ЖƏНЕ ҒЫЛЫМ МИНИСТРЛІГІ
ӘЛ-ФАРАБИ АТЫНДАҒЫ ҚАЗАҚ ҰЛТТЫҚ УНИВЕРСИТЕТІ
Механика-математика факультеті
Информатика кафедрасы
Бітіру жұмысы
Қолданбалы есептерге параллельді алгоритмдерді қолдану
Ғылыми жетекші
ф-м ғ. к., доцент
Кафедра меңгерушісінің рұқсатымен қорғауға жіберілді
ф-м ғ. к., доцент
Алматы, 2010
2. 1. 1 Көпіршік сұрыптау: тізбекті және параллельді әдістері
КІРІСПЕ
Жұмыстың негізгі мақсаты: Сұрыптау есебінің параллельді алгоритмін құру.
Жұмыстың міндеті:
- Көпіршік, жылдам, Шелл сұрыптау әдістерінің тура программасын құру.
- Көпіршік, жылдам, Шелл сұрыптау әдістерінің параллельді есептеу программасын құру.
- Құрылған программалардың нәтижесін MPI арқылы көру және анализ жасау.
Тақырыптың өзектілігі:
1. Параллельді есептеуді қолданудың өзектілігі. Параллельді есептеу дегеніміз - бір уақыт кезінде бірнеше есептеу операцияларын орындайтын есепті шешуге арналған процестер. Суперкомпьютерлер технологиясы мен жоғарғы өнімді есептеулер параллельді есептеудің негізін құрайды. Бір уақытта орындалатын операциялар бір есепті шешуге арналуы керек. Параллельді есептеуді қолданатын аймақтар:
- Ғылымда. Ауа райын болжауда, жаңа технологияларда, жаңалықтарда, ағымдағы космостық ұшу туралы жедел ақпарат алу кезінде, генетика саласында, химиялық есептеулер кезінде.
- Бизнестегі коммерциялық қосымшаларда. Видео конференциялары бар қосымшаларда, жұмыс ортасының бірлесуінде, деректер қорын параллельді өңдеуде, банктық транзакциялар орындау кезінде.
- Білім саласында. Графика мен виртуальды өмірді кеңейту үшін.
2. Параллельді программалауды MPI арқылы іске асыру. MPI (Message Passing Interface) хабарламаны жіберу интерфейсі деп аударылады. Компьютер бірнеше процестерден тұрады, ал әрбір процесс өзінің меншікті жадысымен қамтылған. Процессоры мен оның меншікті оперативті жадысы бар, коммуникациялық желіге қосылған компьютерды хост-машина деп айтады.
Параллельді алгоритм құруда бастапқы мәселе бірнеше бөлік есептерге бөлінеді және оның әр біреуі бір әдіспен шешіледі. Сондықтан бұл жағдайда параллелді программа бірнеше ұқсас фрагменттерден тұрады және барлық процестерде бірдей есептер орындалады. Бұл схема SPMD-моделі (Single Program Multiple Data) деп аталады және хабарламаны жіберу моделінің дербес жағдайы болып табылады.
MPI - "Хабарламаны жіберу интерфейсі"
MPICH (MPI CНameleon) MPI спецификациясын іске асырулардың бірі болып табылады.
Жұмыстың нәтижелері:
- Көпіршік, жылдам, Шелл сұрыптау әдістерінің тізбекті программасы құрылды.
- Көпіршік, жылдам, Шелл сұрыптау әдістерінің параллельді есептеу программасы құрылды.
- Құрылған программалардың нәтижесі МРІ арқылы көріп, талдау жасалды.
1 НЕГІЗГІ БӨЛІМ
1. 1 Қолданбалы есептерге параллельді есептеулерді қолдану
1. 1. 1 Параллельді алгоритмдер
Информатикадағы дәстүрлі жүйелі алгоритмдерге қарсы қойылатын параллель алгоритм дегеніміз - алынған нәтижелерді біріктіруге және нақты ортақ қорытынды алуға негізделген көптеген есептеу құрылғыларында бөліктеп жүзеге асырылатын алгоритм. Кейбір алгоритмдерді жеткілікті жеңіл түрде тәуелсіз орындалатын көріністерге бөлуге болады. Мысалы, 1-ден бастап 1-ға дейінгі сандарды олардың қайсысы жай сандар болатындығына тексеру жұмысын нәтижесінде алынатын көптеген жай сандарды біріктіру арқылы қолда бар әрбір процессорға қандай да бір ішкі жиынды беру арқылы жіктеу (осындай әдіспен, мысалы, GIMPS жобасы жүзеге асырылған) . Екінші жағынан бізге белгілі алгоритмдердің көпшілігі пи санының мәнін параллель орындалатын бөліктерге бөле алмайды, өйткені, олар алгоритмнің алдыңғы итерациясының мәнін талап етеді. Ньютон әдісі немесе үш дене есебі сияқты итеративті сандық әдістер жүйелі алгоритмдер болып табылады. Кейбір рекурсивті алгоритмдердің мысалдарды параллельдіктен ажыратуға бағындыру қиынға соғады. Осындай мысалдардың бірі - графалардағы тереңдікке үңілу.
Параллель алгоритмдер көп процессорлы жүйелерді тұрақты жетілдіру мен қазіргі заманғы процессорлардағы ядролардың санын көбейтуге байланысты маңызды орын алады. Әдетте бірнеше баяу жұмыс жасайтын процессорлары бар компьютерге қарағанда бір ғана жылдам процессоры бар компьютерді құрастыру оңайға соғады (бір ғана өнімділікке жету шарты орындалса) . Алайда процессорлардың өнімділігі негізінен техникалық процесті жетілдірудің (өндіру нормаларын азайту) есебінен арта түседі, бұған микросызбалардың элементтерінің өлшемдері мен жылу бөлінуіне қойылатын шектеулер кедергі жасайды. Аталмыш шектеулерді көп процессорлы өңдеуге көшу арқылы жоюға болады. Бұл әдіс кіші есептеу жүйелері үшін де қолайлы болатыны сөзсіз. Жүйелі алгоритмдердің күрделілігі алгоритмді орындау үшін қажетті қолданылатын жад пен уақыт (процессордың такті саны) көлемінде байқалады. Параллель алгоритмдер тағы бір мынадай қорды қолдануды ескеруді талап етеді: алуан түрлі процессорлар арасындағы байланыстардың ішкі жүйесі. Процессорлар арасындағы алмасудың екі тәсілі бар: жалпы жадты және хабарламаларды беру жүйесі. Жалпы жады бар жүйелер өңделетін мәліметтер үшін қосымша блоктарды енгізуді талап етеді, осылайша олар қосымша процессорларды қолдану барысында нақты шектеулер қояды.
Хабарламаларды жеткізу жүйелері хабарламалардың желісі мен блогы деген ұғымдарды қолданады. Бұл шинадағы қосымша трафикті тудырып, хабарламалардың жүйесін ұйымдастыру үшін жадтың қосымша шығындалуын талап етеді. Қазіргі заманға сай процессорлардың сыртын көркемдегенде хабарламалармен алмасудың алға қойылған мәселені орындауға тигізетін зиянын азайту мақсатында арнайы коммутаторлар (кроссбарлар) қарастырылуы мүмкін.
Параллель алгоритмдерді қолдануға қатысты қиындықтардың бірі - жүктемені теңгеру. Мысалы, 1-ден 1-ға дейінгі аралықтағы жай сандарды тауып, қолда бар процессорларға оңай үлестіруде байқалады. Алайда кейбір процессорлар көбірек жұмыс көлемін алса, екінші біреулері өңдеуді ерте аяқтап, бос тұрып қалуы мүмкін. Жүктемені теңгеруге қатысты кедергілер гетерогенді есептеу орталарын қолдану барысында жиілей түседі. Мұндай орталарда есептеу элементтері өнімділігі мен қол жетімділігі бойынша айтарлықтай ерекшеленеді (мысалы, грид-жүйелерде) .
Параллель алгоритмдердің үлестірілген алгоритмдер деп аталатын бір түрі осындай өңдеулердің ерекшеліктерін ескере отырып, кластерлер мен үлестірілген есептеу жүйелерінде қолдану мақсатында арнайы жасалады. Көп процессорлы жүйелерді пайдалану параллель есептеулердің нақты ерекшеліктерін ескеру және меңгеруді талап етеді. Аталмыш мақалада өзара ортақ қасиеттері бар аппаратты тұғырнамалардың кең класы үшін параллель бағдарламалаудың ерекшеліктері баяндалады.
Көп процессорлы есептеу жүйелері (есептеу кластерлері) кеңінен қолданылып жүр - бұл көп процессорлы серверлер мен еңбек қажырлығы мол есептеу тәжірибелерін ұйымдастыру үшін қолданылатын суперкомпьютерлер, ақпараттық және есептеу қорларын ажыратуға мүмкіндік беретін кәсіпорын ауқымындағы Intranet-желілері. Есептеу кластерлерінде түрлі сәулет ғимараттары мен операциялық қоршаған ортасы болады, бірақ, бағдарламалау барысында оларда жиі жағдайда бірдей қиындықтар туындайды. Осының барлығы үлестірілген есептеу құралдарын жалпы ұжымдық қор ретінде қолдануға жаңаша көзқараспен қарауға итермелейді. Біз осы «мұзтаудың» кем дегенде аз бөлігін баяндауға тырысып көреміз.
Процессорлардың жұмысының тактілік жиілігі шамамен олардың өнімділігіне сәйкес келеді деп есептесек, онда қазіргі таңда жасалатын секундына 103 млн. операция (МОПС) - бұл бір ғана процессордың өзінде қол жеткізуге мүмкін болатын өнімділік. Жыл сайын шығарылатын процессорлардың тактілік жиілігі артып отыратындықтан максимал өнімділікті шамамен 106-108 МОПС арттыруға болады деген үміт жоқ емес. Алайда мұндай процессорлардың молекулалық шектеулердің салдарынан уақыт бойынша сызықты экстраполяциясы жоқ. Өнімділігі 108 МОПС артық процессорлар қазіргі заманғы процессорлармен салыстырғанда басқа құрылысы болуы мүмкін, не болмаса оларды құрастыру мүмкін болмайды. Осыдан шығатындай, есептеу техникасын дамытудың жалғыз жоспары - бұл көп процессорлы есептеулерді жасау. Нәтижесінде параллель алгоритмдер - келешекте есептерді шешуде өнімділікті жоғарылатудың ұтымды тәсілі.
Параллель алгоритмді орындау барысында әрбір процессор элементінде үлкен емес өзгерістері бар жоғарыда қарастырылған жүйелі алгоритм жүзеге асырылады. Процессорлық элементтердің арасында нөлдік нөмірі бар элемент ерекшеленеді. Есеп жөніндегі мәліметтер диск жадынан нөлдік процессордың көмегімен оқылады және қалғандарына беріледі. Әрі қарай нөлдік процессорда бүтін сандылық шартын ескермегенде бастапқы есеп шешіледі, ал қалған процессорлар осы уақытта күту режимінде болады. Есептеу процесінде нөлдік элементте параллель есептеулерді ұйымдастыруға арналған қажетті анықтамалық ақпарат жинақталады.
Кез келген процессорды іске қосу үшін (әрі қарай оның ішінде нөлдікті де) оның оперативті жадына мынадай массивтер жіберіледі: ISB, ISN және бағалау есептерін бейнелеу үшін қолданылатын h массивінің бір бөлігі. m компоненттен тұратын бүтін санды ISB массиві базисті айнымалылардың нөмірлерінен құралады, n өлшемді базисті емес айнымалыларға арналған бүтін санды ISN массиві қандай жоғарғы немес төменгі шекараларда айнымалылардың орналасқандығын анықтайды, ал базисті айнымалылар үшін ISN массивінің көмегімен базистегі орындардың нөмірлері жазылады. h массивінің қай бөлігі берілетіндігі бағалау есептерін шешу басталатын деңгеймен анықталады.
Нөлдік процессордан қандай да бір процессорлық элементті жүктеу керек болсын. Айталық, k деңгейде нөлдік процессорда тармақталу үшін xj айнымалысы таңдалып алынсын және P-j < P+j. Нөлдік процессорда P-j штрафына сәйкес келетін бағалау есебі шешілетін болады. Егер fi - P+j > ri болса, онда мәліметтер белгіленген процессорлық элементке жіберіледі.
Нөлдік процессорлық элементте P+j мәніне сәйкес келетін тармақ белгіленеді (h (3, k) шамасына 1 мәні беріледі) . Қабылдаушы жақта k-ға қарағанда анағұрлым жоғары деңгейге ие белгіленбеген барлық тармақтар белгіленеді. ISB тізімінің негізінде базисті матрицаларға қарсы матрицаларды қайта құру процедурасының (бұл процедураны тағы қайталау деп те атайды) көмегімен В-1 матрицасы тұрғызылады. ISB, ISN және h мәліметтері аталмыш процессорлық элементте бірінші бағалау есебін қалыптастыру үшін жеткілікті.
Параллель алгоритмде әрбір процессорлық элементте есептеу процесін бастаған жөн, мүмкіндігінше, жоғары жатқан тармақтан бастаған дұрыс болады. Ол үшін әрбір процессорлық элементте ISB және ISN массивтері сақталып қалады, олар сұрау жасалынған соң бірденнен келесі процессорға беріледі. Егер қандай да бір процессор жаңа ri рекордын алса, онда бұл ақпарат қалғандарына жіберіледі. ri алып болғаннан кейін h(4, k) -h(5, k) £ ri теңсіздігінің орындалуы тексеріледі, мұндағы k аталмыш процессорлық элементте алгоритм бастау алған деңгейге сәйкес келеді. Осы теңсіздік орындалған жағдайларда жаңа тапсырмаға сұрау жасалады. Алынған ri мәні һ массивіндегі белгіленген және белгіленбеген тармақтарды тексеру үшін қолданылады. ISB, ISN массивтерінің ақпараттары өзекті болмай қалуы мүмкін (ri жаңа мәнінде осы массивтерге сәйкес келетін тармақ белгіленеді) . Осындай жағдайда ISB мен ISN жаңа нұсқалары дайындалады және нөлдік процессорлық элементке осы массивтерге қатысты деңгейдің өзгерісі жөнінде хабарлама жіберіледі. Есеп шешіледі, егер ri = f0 рекорды қабылданған болса немесе барлық процессорлық элементтерде нөлдік деңгейге қол жеткізілген болса. Есеп туралы бастапқы мәліметтерді беру MPI BCAST блоктау функциясының көмегімен жүзеге асырылады. [7] Әрі қарай барлық процестер асинхронды режимде орындалады және мәліметтермен алмасу блокталмаған функциялар арқылы жүзеге асырылады. Процессорлық элементте жұмыстың күтілуі PROBE функциясынің қатысуымен іске асады. Хабарламалар ISEND және WAIT арқылы орындалады, ал қабылдау процесі RECV жүзеге асырылады. Аталмыш процессорға хабарлама бар - жоғын туралы сұрау IPROBE функциясымен жасалады. Қысқа хабарламалар үшін үш мақсатты және бір ғана заттық саны бар екі еселік дәлдіктегі құрылым қолданылады. Есепті алгоритмнің орындауына жіберу (ISB, ISN және h масивінің бөлігі) қосфазалы хаттама арқылы орындалады. Блоктаушы функциялардың көмегімен шешімді алғаннан кейін нөлдік процессорлық элементке есепті шешу бойынша өзге процессорлардан келген статистикалық мәліметтер саналады.
- Параллельді алгоритмдерді ұйымдастыру
Үлестірілген жады бар процессорларды қолдану көп процессорлы есептеу жүйелерін құрастырудың тағы бір жалпы әдісі болып табылады. Мұндай жүйелердің өзектілігі жоғары өнімді кластерлік есептеу жүйелерінің кеңінен дамуына сай соңғы уақыттарда өсуде.
Параллель бағдарламалаудың көптеген қиындықтары (есептеулердің бәсекесі, тығырықтар, серияларға бөлу) жалпы және үлестірілген жадқа ие жүйелер үшін ортақ болып табылады. Параллель есептеулерді үлестірілген жадтан ажырататын мезет әр түрлі процессорлардағы бағдарламаның параллель бөліктерінің өзара әсерлесуі хабарламаларды тасымалдау арқылы қамтамасыз етілетіндігіне негізделген (message passing) . Үлестірілген жады бар процессор жалпы жады бар көп процессорлы жүйедегі процессорға қарағанда әдетте анағұрлым күрделі есептеу құрылғысы екендігі анық. Осындай ерекшеліктерді ескеру үшін әрі қарай үлестірілген жады бар процессорды есептеу сервері деп атайтын боламыз (сервер ретінде ішінара жалпы жады бар көп процессорлы жүйе де қолданылуы мүмкін) . Төменде көрсетілген барлық тәжірибелерді жүргізу үшін процессорлары Pentium IV, 1300 Mhz, 256 RAM, 100 Mbit Fast Ethernet болатын 4 компьютер қолданылды. Үлестірілген жады бар жүйелерде параллель есептеулерді ұйымдастыру барысында алдымен шешуге тиісті мәселе әдетте өңделетін мәліметтерді есептеу серверлерінің арасында бөлу тәсілдерін таңдауға негізделеді. Мұндай бөлудің тиімділігі серверлердегі есептеулерді жергіліктендірудің қол жеткізілген дәрежесімен анықталады (хабарламаларды жеткізудегі үлкен уақыттық тосқауылдарға қатысты серверлердің өзара әсерлесу қарқыны минимал болуы тиіс) .
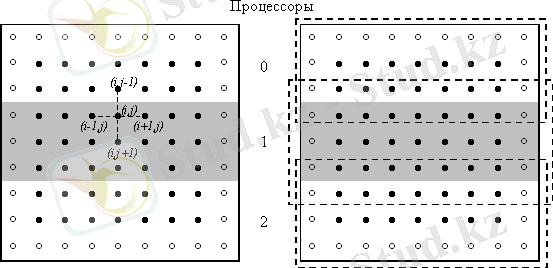
1 сурет. Есептеу облысын процессорлар арасында таспалы бөлу (дөңгелектер тордың шекаралық түйіндерін береді)
Қарастырылып отырған Дирихле есебін шешуге қатысты оқу мәселесінде мәліметтерді бөлудің екі түрлі тәсілі бар - есептеу торының бірөлшемді немесе таспалы сызбасы (1 сурет) не болмаса екіөлшемді немесе блокты бөлінуі (2 сурет) . Оқу материалы әрі қарай бірінші тәсіл мысалында баяндалатын болады; блокты сызба кейінірек қысқа нұсқада қарастырылады. Мәліметтерді жіктеудің осындай тәсіліне ие есептеулерді ұйымдастыру барысында қандай да бір жолақты өңдеуді жүзеге асыратын процессорға есептеу торының алдыңғы және кейінгі жолақтарының шекаралық жолдары көшірілуі тиіс екендігіне баса назар аударған жөн. Көшірілген жолақтың шекаралық жолдары есептеу барысында ғана қолданылуы тиіс. Осы жолдарды қайта есептеу бастапқы орнындағы жолақтарда орындалады. Осылайша шекаралық жолдарды көшіру тор әдісінің әрбір кезекті итерациясы алдында жүзеге асырылуы тиіс. Жолақтың жолдарын нөмірлеу үшін 0 және M+1 жолдары көрші жолақтардан көшірілген шекаралық жолдар болатын, ал процессордың өзіндік жолағының жолдары 1-ден М-ге дейінгі нөмірлерге ие болатын нөмірлеуді қолданатын боламыз.
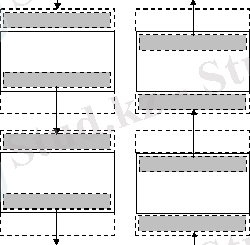
2 сурет. Көрші процессорлар арасындағы шекаралық жолдарды беру сызбасы
Көрші процессорлар арасындағы шекаралық жолдармен алмасу процедурасы екі кезекті операцияларға жіктелуі мүмкін, оның біріншісінде әрбір процессор өзінің төменгі шекаралық жолын келесі процессорға беріп, дәл осындай жолды алдыңғы процессордан қабылдап алады. Жолды берудің екінші бөлігі кері бағытта жүзеге асырылады: процессорлар өздерінің жоғарғы шекаралық жолдарын өздерінің алдыңғы көршілеріне береді және келесі процессорлардан келетін жолдарды қабылдайды. Осындай мәліметтерді беру операцияларын жалпы күйде төмендегіше бейнелеуге болады (ықшамды болу үшін алмасу процедурасының бірінші бөлігін ғана қарастырамыз) :
// төменгі шекаралық жолды келесі
// процессорға беру және берілетін жолды
// алдыңғы процессордан қабылдау
if ( ProcNum != NP-1 ) Send(u[M] [*], N+2, NextProc) ;
if ( ProcNum != 0 ) Receive(u[0] [*], N+2, PrevProc) ;
(қабылдау-беру процедураларын жазбалау үшін стандартқа жақын MPI форматы қолданылады, мұндағы бірінші және екінші параметрлер жіберілетін мәліметтер мен олардың көлемдерін сипаттайды, ал үшінші параметр мәліметтерді жіберу адресатын (Send операциясы үшін) немесе алу көзін (Receive операциясы үшін) анықтайды) .
Мәліметтерді беру үші екі түрлі механизм іске қосылады. Жіберу операциясына қозғаушы күш болған олардың бірінде мәліметтерді жіберуге қатысты барлық іс-әрекеттер толығымен аяқталмағанша бағдарламаларды орындау уақытша тоқтатылады (яғни процессор - адресат барлық оған келетін мәліметтерді алып біткенше тоқтайды) . Осындай тәсілмен жүзеге асырылатын қабылдау-беру операциялары әдетте синхронды немесе блоктаушы деп аталады. Тағы бір әдіс - асинхронды немесе блоктамайтын тасымал - ол қабылдау-беру операциялары тасымал процесіне ғана түрткі болып, осы сатыда өздерінің жұмыстарын аяқтайтындығынан тұрады. Нәтижесінде ұзақ уақытқа созылатын коммуникациялық операциялардың аяқталуын күтпей-ақ, бағдарламалар қажеттілік дәрежесіне сай берілетін мәліметтердің дайындығын тексере отырып, өздерінің есептеулерін жүргізе береді. Операциялардың осы қос нұсқасы да параллель есептеулерді ұйымдастыруда кеңінен қолданылады және олардың да өзіндік артықшылықтары мен кемшіліктері бар. Ереже бойынша синхронды тасымалдау процедуралары қолдануға оңай және анағұрлым сенімді; блоктамайтын операциялар мәліметерді тасымалдау және есептеу процестерін біріктіре алады, бірақ, әдетте олардың салдарынан бағдарламалау процесі күрделеніп кетуі мүмкін. Барша осындай мысалдарды ескере отырып, мәліметтерді тасымалдауды ұйымдастыру үшін блоктау типіндегі қабылдау-беру операциялары қолданылатын болады.
Жоғарыда келтірілген мәліметтерді қабылдау-берудің блоктаушы операцияларының жүйелік қасиеті (алдымен Send, содан соң Recieve) жолдарды тасымалдаудың қатаң жүйелі сызбасына келіп тіреледі, өйткені, барлық процессорлар бірмезгілде Send операциясына жүгінеді және күту режиміне ауысады. Тасымалданатын мәліметтерді қабылдауға дайын болатын бірінші процессор - бұл NP-1 нөмірлі сервер. Нәтижесінде NP-2 процессоры өзінің шекаралық жолын беру операциясын орындап, NP-3 процессорынан жолды қабылдауға көшеді және т. с. с. Осындай операцияларды қайталау саны NP-1 тең. Дәл осылайша жолдарды өңдеу алдында шекаралық жолдарды тасымалдаудың екінші бөлігі де іске асады (2 сурет) . Қарастырылған мәліметтерді тасымалдау операцияларының жүйелі сипаты амалдарды кезегімен орындау тәсілін таңдаумен анықталады. Осы амалдарды орындау кезегін жұп және тақ нөмірлі процессорлар үшін қабылдау және беру амалдарының кезектесуі арқылы өзгертіп көрейік:
// төменгі шекаралық жолды келесі
// процессорға беру және берілетін жолды
// алдыңғы процессордан қабылдау
if ( ProcNum % 2 == 1 ) { // тақ процессор
if ( ProcNum != NP-1 ) Send(u[M] [*], N+2, NextProc) ;
if ( ProcNum != 0 ) Receive(u[0] [*], N+2, PrevProc) ;
} else { // жұп нөмірлі процессор
if ( ProcNum != 0 ) Receive(u[0] [*], N+2, PrevProc) ;
if ( ProcNum != NP-1 ) Send(u[M] [*], N+2, NextProc) ;
}
Аталмыш тәсіл барлық қажетті беру операцияларын екі кезекті қадамның ішінде-ақ орындауға мүмкіндік береді. Бірінші қадамда барлық тақ нөмірлі процессорлар мәліметтерді жібереді, ал жұп нөмірлі процессорлар осы мәліметтерді қабылдайды. Екінші қадамда процессорлардың рөлдері ауысады - жұп процессорлар Send амалын орындаса, тақ процессорлар Reciеve қабылдау операциясын жүзеге асырады.
Көрші процессорларды өзара әсерлестіру мақсатындағы қабылдау-беру операцияларынң жүйелі сипаты параллель есептеулер тәжірибесінде кеңінен қолданылады. Параллель бағдарламалардың көптеген базалық кітапханаларында осындай амалдарды қолдауға арналған процедуралар бар. Мысалы, MPI стандартында Sendrecv операциясы қарастырылған, оны қолдану арқылы бағарлама кодының алдыңғы көрінісін қысқаша түрде жазуға болады:
// төменгі шекаралық жолды келесі
// процессорға беру және жіберілген жолды
// келесі процессордың қабылдауы
Sendrecv(u[M] [*], N+2, NextProc, u[0] [*], N+2, PrevProc) ;
Мұндай Sendrecv біріккен қызметін жүзеге асыру мынадай жағдайға сай етіп жасалады: беру немесе қабылдау операциясының бірін орындау қажет болмайтын шеткі процессорлардың нақты жұмысын қамтамасыз ету үшін және тығырықты жағдайлардан шығу үшін және барлық мәліметтерді тасымалдауды параллель жүзеге асыру мүмкіндігіне ие болу үшін процессорлардағы тасымал процедураларын жүйелі етуді ұйымдастыру.
1. 1. 3 Параллельді есептеулердің технологиялары (MPI, Open/MP)
... жалғасыСіз бұл жұмысты біздің қосымшамыз арқылы толығымен тегін көре аласыз.
- Іс жүргізу
- Автоматтандыру, Техника
- Алғашқы әскери дайындық
- Астрономия
- Ауыл шаруашылығы
- Банк ісі
- Бизнесті бағалау
- Биология
- Бухгалтерлік іс
- Валеология
- Ветеринария
- География
- Геология, Геофизика, Геодезия
- Дін
- Ет, сүт, шарап өнімдері
- Жалпы тарих
- Жер кадастрі, Жылжымайтын мүлік
- Журналистика
- Информатика
- Кеден ісі
- Маркетинг
- Математика, Геометрия
- Медицина
- Мемлекеттік басқару
- Менеджмент
- Мұнай, Газ
- Мұрағат ісі
- Мәдениеттану
- ОБЖ (Основы безопасности жизнедеятельности)
- Педагогика
- Полиграфия
- Психология
- Салық
- Саясаттану
- Сақтандыру
- Сертификаттау, стандарттау
- Социология, Демография
- Спорт
- Статистика
- Тілтану, Филология
- Тарихи тұлғалар
- Тау-кен ісі
- Транспорт
- Туризм
- Физика
- Философия
- Халықаралық қатынастар
- Химия
- Экология, Қоршаған ортаны қорғау
- Экономика
- Экономикалық география
- Электротехника
- Қазақстан тарихы
- Қаржы
- Құрылыс
- Құқық, Криминалистика
- Әдебиет
- Өнер, музыка
- Өнеркәсіп, Өндіріс
Қазақ тілінде жазылған рефераттар, курстық жұмыстар, дипломдық жұмыстар бойынша біздің қор #1 болып табылады.

Ақпарат
Қосымша
Email: info@stud.kz