Типы моделей данных: эволюция и сравнительный анализ иерархической, сетевой и реляционной моделей

Тип работы: Реферат
Бесплатно: Антиплагиат
Объем: 17 страниц
В избранное:
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ
РЕСПУБЛИКИ КАЗАХСТАН
КАЗАХСКИЙ НАЦИОНАЛЬНЫЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ
ИМЕНИ КАНЫША ИМАНТАЕВИЧА САТПАЕВА
КАФЕДРА «ТЕХНИЧЕСКАЯ ЭКСПЕРТИЗА и ОЦЕНКА»
РЕФЕРАТ
Тема: Типы моделей данных
Специальность 541530 - «Информационные системы в экономике» (бакалавриат)
Выполнила: студентка 3 курса
дневного отделения
группы ИСЭб - 03 - 2р
Быкова У.
Приняла:
Чакеева К. С.
Алматы
2005
Оглавление. стр.
Введение.
Эволюция систем баз данных. 3
I Модели данных 4
1. 1 Иерархическая модель данных . . . 5
1. 2 Реляционная модель данных7
II Обоснование концепции БД и ее основные положения14
Заключение 16
Использованная литература. . 17
Введение.
Эволюция систем БД.
По сути дела БД - это просто множество информации, существующее долгое время, часто в течение многих лет. Обычно термином « база данных » обозначается множество данных, управляемое системой управления базой данных , называемой также СУБД (DBMS), или просто системой базы данных . Предполагается, что СУБД:
- Обеспечивает пользователю возможность создавать новые БД и определять их схему (логическую структуру данных) с помощью специального языка, получившего названиеязыка определения данных.
- Позволяет «запрашивать» данные («запрос» в терминологии БД означает вопрос по поводу данных) и изменять их с помощью подходящего языка, называемогоязыком запросов, илиязыком манипулирования данными.
- Поддерживает хранение очень больших массивов данных, измеряемых гигабайтами и более, в течение долгого времени, защищая их от случайной порчи или неавторизованного использования и обеспечивая модификацию БД и доступ к данным путем запросов.
- Контролирует доступ к данным сразу множества пользователей, не позволяя запросу одного из них влиять на запрос другого и не допуская одновременного доступа, который может случайно испортить данные.
Когда разработчики начинают проектировать новые базы данных им необходимо иметь четкое представление о существующих моделях данных.
В данной работе представлена краткая, но весьма полезная и познавательная информация о моделях представления данных.
В первом и втором разделах реферата отображены сведения о двух типах моделей: иерархической и реляционной.
В заключении мной подведены итоги и предоставлены некоторые рекомендации начинающим разработчикам информационных систем, которые основаны на реляционной БД. Советы, данные мной, являются весьма лаконичными и полезными, они могут пригодиться в работе с БД.
I Модели данных.
При проектировании БД используются три основные модели представления о данных:
- иерархическая;
- сетевая;
- реляционная.
В иерархической модели связь между данными является иерархической с четко установленными уравнениями вложности.
Данные представляются в виде поля - сегмент - запись.
С помощью сегментов описываются объекты предметной области.
Сегмент состоит из множества полей, которые описывают свойства объектов.
Запись представляет собой полную совокупность иерархически-упорядоченных сегментов. При этом всегда имеется корневой сегмент.
В сетевой модели используются понятия элемент - запись - набор.
Объект описывается в виде записи, а его свойства в виде совокупностей полей, составляющих запись.
Набор служит для организации связей между записями. Каждая порожденная запись может иметь более одной исходной записи.
Сетевая структура может быть простой или сложной, в зависимости от того, какова связь исходно-порожденной, также может содержать циклы.
Сеть по сравнению с иерархией является более общей структурой.
К достоинствам сетевой модели относятся:
- простота реализации связи многие-ко-многим;
- разделение данных из связей;
- легкость выполнения операций включение и удаление;
А к недостаткам:
- сложность представления данных как на логическом, так и на физическом уровнях;
- сложность программ при реализации СУБД для сетевой модели.
Говоря о реляционной модели, то она построена на системе отношений. Автором модели является Е. Кодд. В реляционной модели используется понятие отношение-атрибут.
Объект представляется в виде отношения, а его свойства в виде совокупности атрибутов.
Базу данных можно представить в следующем виде:
R 1 (A 11 , A 12 , …A 1N1 ) где R i - множество отношений
R 2 (A 21 , A 22 , …A 2N2 ) А - множество атрибутов
. .
R m (A m1 , A m2 , …A mNn )
Экземпляр каждого отношения представляется в идее таблицы. Совокупность всех значений одного атрибута называется доменом . Строка в таблице - кортежем .
Основным свойством реляционной модели является то, что связи между кортежами представлены исключительно значениями данных в столбцах, полученных из общего домена.
Обработка отношений осуществляется с помощью операций реляционной алгебры, предложенных Коддом.
К достоинствам реляционной модели относятся:
- простота и наглядность представления данных;
- наличие теоретического обоснования, т. к. модель основана на хорошо проработанной теории отношений;
- наличие математического аппарата - реляционной алгебры;
Недостатками же модели являются:
- сложность реализации связи один-ко-многим и многие-ко-многим, которая ведет к дублированию данных.
Теперь, рассмотрев вкратце информацию о существующих моделях данных, можно перейти к более углубленному описанию.
- Иерархическая модель.
Иерархическая модель является наиболее простой среди всех датологических моделей. Исторически она появилась первой среди всех моделей, и именно эту модель поддерживает первая из зарегистрированных промышленных СУБД фирмы IBM.
Появление иерархической модели связано с тем, что в реальном мире очень многие связи соответствуют иерархии, когда один объект выступает покровительски, а с ним может быть связано множество подчиненных объектов.
Иерархия проста и естественна в отображении взаимосвязей между классами объектов.
Основными информационными единицами иерархической модели является БД, сегмент и поле.
Поле данных определяется как минимальная неделимая единица данных, доступная пользователю с помощью СУБД.
Например, если в задачах требуется печатать в документах адрес клиента, но не требуется дополнительного адреса, т. е. города, улицы, дома, квартиры, то можем принять весь адрес за элемент данных, и он будет храниться полностью, а пользователь сможет получить его только как полую строку символов из БД. Если же в задачах существует анализ частей, составляющих адрес, например, города, где расположен клиент, то необходимо выделить город как отдельный элемент данных, и только в этом случае пользователь может получить к нему доступ и выполнить, например, запрос на поиск всех клиентов, которые проживают в конкретном городе.
однако, если пользователю понадобится и полный адрес клиента, то остальную информацию по адресу также необходимо хранить в отдельном поле, которое может быть названо, например, сокращенный адрес. В этом случае для каждого клиента в БД хранится как город, так и сокращенный адрес.
Сегмент в терминологии американской ассоциации по БД называется записью, при этом в рамках иерархической модели определяются два понятия:
- тип сегмента (тип записи) ;
- экземпляр сегмента (экземпляр записи) .
Тип сегмента - это поименованная совокупность типов элементов данных в него входящих.
Экземпляр сегмента образуется из конкретных значений полей или элементов данных также в него входящих.
Каждый тип сегмента в рамках иерархической модели образует некоторый набор однородных записей. Для возможности различия отдельных записей в данном наборе каждый тип сегмента должен иметь ключ или набор ключевых атрибутов.
Ключом называется набор элементов данных, однозначно идентифицирующих экземпляр сегмента. Например, рассматривая тип сегмента, описывающего сотрудников организации, необходимо выделить те характеристики сотрудника, которые могут его однозначно идентифицировать в рамках БД предприятия. Если предположить, что на предприятии могут работать однофамильцы, то вероятно наиболее надежным будет идентифицировать сотрудника по его табельному номеру. Однако, если строить БД, содержащую описание множества граждан, например, города, то скорее всего придется в качестве ключа выбрать совокупность полей, которые отражают его паспортные данные.
В иерархической модели сегменты объединяются в ориентированный древовидный граф. При этом полагают, что направленные ребра графа отражают иерархические связи между сегментами. Каждому экземпляру сегмента, стоящему выше по иерархии и соединенному с данным типом сегмента, соответственно несколько множеств экземпляров подчиненного типа сегмента.
Тип сегмента, находящегося на более высоком уровне иерархии, называется логическим исходным по отношению к типам сегментов, соединенным с данными, направленных иерархическими ребрами, которые называются логическими подчиненными по отношению к этому типу сегмента.
Иногда исходные сегменты называют сегментами-придатками, а подчиненные сегменты - сегментами-потомками.
Рис. 1 Иерархические связи между сегментами.
сегмент типа А
сегмент типа В сегмент типа С
Схема иерархической БД представляет собой совокупность отдельных деревьев, каждое дерево в рамках модели называется физической базой данных .
Каждая физическая БД удовлетворяет следующим иерархическим ограничениям:
- в каждой физической БД существует один корневой сегмент, т. е. сегмент, у которого нет логически исходного (родительского) типа сегмента;
- каждый логический исходный сегмент может быть связан с произвольным числом логических подчиненных сегментов;
- каждый логический подчиненный сегмент может быть связан только с одним логическим исходным (родительским) сегментом.
Необходимо понимать различие между сегментом и типом сегмента (оно такое же как между типом переменной и самой переменной) :
- сегмент является экземпляром типа сегмента.
Например, тип сегмента может быть группа (№ группы, староста) и сегмент этого типа (541530, Петров А. ) .
Рис. 2 Структура иерархического дерева.
А
В С
D Е
Язык описания данных иерархической модели.
В рамках иерархической модели выделяют языковые средства описания данных DDL (Data Definition Language) и средства манипулирования данными DML (Data Manipulation Language) .
Каждая физическая база описывается набором операторов, определяющих как ее логическую структуру, так и структуру хранения БД.
Описание начинается с оператора DBD (Data Base Definition) .
DBD Name = <имя БД>, Access = <способ доступа>.
Способ доступа определяет способ операции взаимосвязей физических записей. Определено 5 способов доступа:
- HSAM (иерархический последовательный метод) ;
- HISAM (иерархический индексно последовательный метод) ;
- EDAM (иерархический прямой метод) ;
- HIMAM (иерархический индексно прямой метод) ;
- INDEX (индексный метод) . Реляционная модель данных.
Основы реляционной модели данных были впервые изложены в статье Е. Кодда в 1970 г. Эта работа послужила стимулом для большого количества статей и книг, в которых реляционная модель получила дальнейшее развитие. Наиболее распространенная трактовка реляционной модели данных принадлежит К. Дейту.
Согласно Дейту, реляционная модель состоит из трех частей:
- Структурной части
- Целостной части
- Манипуляционной части
Структурная часть описывает, какие объекты рассматриваются реляционной моделью. Постулируется, что единственной структурой данных, используемой в реляционной модели, являются нормализованные n-арные отношения.
Целостная часть описывает ограничения специального вида, которые должны выполняться для любых отношений в любых реляционных базах данных. Это целостность сущностей и целостность внешних ключей .
Манипуляционная часть описывает два эквивалентных способа манипулирования реляционными данными - реляционную алгебру и реляционное исчисление .
Любые данные, используемые в программировании, имеют свои типы данных.
Реляционная модель требует, чтобы типы используемых данных были простыми .
Для уточнения этого утверждения рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
- Простые типы данных
- Структурированные типы данных
- Ссылочные типы данных
Простые, или атомарные, типы данных не обладают внутренней структурой. Данные такого типа называют скалярами . К простым типам данных относятся следующие типы:
- Логический
- Строковый
- Численный
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
- Целый
- Вещественный
- Дата
- Время
- Денежный
- Перечислимый
- Интервальный
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика ( смысл ) данных . Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как единого целого.
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
- Массивы
- Записи (Структуры)
С математической точки зрения массив представляет собой функцию с конечной областью определения. Например, рассмотрим конечное множество натуральных чисел
называемое множеством индексов. Отображение

из множества
 во множество вещественных чисел
во множество вещественных чисел
 задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса
задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса
 называется элементом массива, соответствующим
называется элементом массива, соответствующим
 . Аналогично можно задавать многомерные массивы.
. Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов
 , каждый из которых принадлежит типу
, каждый из которых принадлежит типу
 . Таким образом, запись
. Таким образом, запись
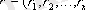 есть элемент множества
есть элемент множества
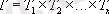 . Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
. Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру , используемую на том же уровне абстракции , что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Ссылочный тип данных ( указатели ) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, графов, рекурсивных структур.
Собственно, для реляционной модели данных тип используемых данных не важен. Требование, чтобы тип данных был простым , нужно понимать так, что в реляционных операциях не должна учитываться внутренняя структура данных . Конечно, должны быть описаны действия, которые можно производить с данными как с единым целым, например, данные числового типа можно складывать, для строк возможна операция конкатенации и т. д.
С этой точки зрения, если рассматривать массив, например, как единое целое и не использовать поэлементных операций, то массив можно считать простым типом данных. Более того, можно создать свой, сколь угодно сложных тип данных, описать возможные действия с этим типом данных, и, если в операциях не требуется знание внутренней структуры данных, то такой тип данных также будет простым с точки зрения реляционной теории. Например, можно создать новый тип - комплексные числа как запись вида
 , где
, где
 . Можно описать функции сложения, умножения, вычитания и деления, и
все действия с компонентами
. Можно описать функции сложения, умножения, вычитания и деления, и
все действия с компонентами
 и
и
 выполнять только
внутри
этих операций. Тогда, если в действиях с этим типом использовать
только
описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
выполнять только
внутри
этих операций. Тогда, если в действиях с этим типом использовать
только
описанные операции, то внутренняя структура не играет роли, и тип данных извне выглядит как атомарный.
Именно так в некоторых пост-реляционных СУБД реализована работа со сколь угодно сложными типами данных, создаваемых пользователями.
В реляционной модели данных с понятием тип данных тесно связано понятие домена, которое можно считать уточнением типа данных.
Домен - это семантическое понятие. Домен можно рассматривать как подмножество значений некоторого типа данных имеющих определенный смысл. Домен характеризуется следующими свойствами:
- домен имеет уникальное имя (в пределах базы данных) ;
- домен определен на некотором простом типе данных или на другом домене;
- домен может иметь некоторое логическое условие , позволяющее описать подмножество данных, допустимых для данного домена;
- домен несет определенную смысловую нагрузку .
Например, домен
 , имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:
, имеющий смысл "возраст сотрудника" можно описать как следующее подмножество множества натуральных чисел:
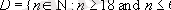
Если тип данных можно считать множеством всех возможных значений данного типа, то домен напоминает подмножество в этом множестве.
Отличие домена от понятия подмножества состоит именно в том, что домен отражает семантику , определенную предметной областью. Может быть несколько доменов, совпадающих как подмножества, но несущие различный смысл. Например, домены "Вес детали" и "Имеющееся количество" можно одинаково описать как множество неотрицательных целых чисел, но смысл этих доменов будет различным, и это будут различные домены.
Основное значение доменов состоит в том, что домены ограничивают сравнения . Некорректно, с логической точки зрения, сравнивать значения из различных доменов, даже если они имеют одинаковый тип. В этом проявляется смысловое ограничение доменов. Синтаксически правильный запрос "выдать список всех деталей, у которых вес детали больше имеющегося количества" не соответствует смыслу понятий "количество" и "вес".
Понятие домена помогает правильно моделировать предметную область. При работе с реальной системой в принципе возможна ситуация когда требуется ответить на запрос, приведенный выше. Система даст ответ, но, вероятно, он будет бессмысленным.
Не все домены обладают логическим условием, ограничивающим возможные значения домена. В таком случае множество возможных значений домена совпадает с множеством возможных значений типа данных.
Не всегда очевидно, как задать логическое условие, ограничивающее возможные значения домена. Трудно привести условие на строковый тип данных, задающий домен "Фамилия сотрудника". Ясно, что строки, являющиеся фамилиями не должны начинаться с цифр, служебных символов, с мягкого знака и т. д. Но вот является ли допустимой фамилия "Г"? Нет! А может кто-то назло так себя назовет. Трудности такого рода возникают потому, что смысл реальных явлений далеко не всегда можно формально описать. Просто мы, как все люди, интуитивно понимаем, что такое фамилия, но никто не может дать такое формальное определение, которое отличало бы фамилии от строк, фамилиями не являющимися. Выход из этой ситуации простой - положиться на разум сотрудника, вводящего фамилии в компьютер.
Фундаментальным понятием реляционной модели данных является понятие отношения . В определении понятия отношения будем следовать книге К. Дейта.
Определение 1. Атрибут отношения есть пара вида <Имя_атрибута : Имя_домена>.
... продолжениеВы можете абсолютно на бесплатной основе полностью просмотреть эту работу через наше приложение.
- Информатика
- Банковское дело
- Оценка бизнеса
- Бухгалтерское дело
- Валеология
- География
- Геология, Геофизика, Геодезия
- Религия
- Общая история
- Журналистика
- Таможенное дело
- История Казахстана
- Финансы
- Законодательство и Право, Криминалистика
- Маркетинг
- Культурология
- Медицина
- Менеджмент
- Нефть, Газ
- Искуство, музыка
- Педагогика
- Психология
- Страхование
- Налоги
- Политология
- Сертификация, стандартизация
- Социология, Демография
- Статистика
- Туризм
- Физика
- Философия
- Химия
- Делопроизводсто
- Экология, Охрана природы, Природопользование
- Экономика
- Литература
- Биология
- Мясо, молочно, вино-водочные продукты
- Земельный кадастр, Недвижимость
- Математика, Геометрия
- Государственное управление
- Архивное дело
- Полиграфия
- Горное дело
- Языковедение, Филология
- Исторические личности
- Автоматизация, Техника
- Экономическая география
- Международные отношения
- ОБЖ (Основы безопасности жизнедеятельности), Защита труда
